
Date: 2018/08/02
Location: The Pearl, San Francisco
O11ycon 2018 was a conference organized by the team at Honeycomb.io focused on exploring and developing the concept of observability in the context of distributed systems engineering. Called a co-creation event and y-know, hippieshit by organizer Rachel Chalmers, the conference was open-ended, and I got the pleasure to participate and even present on stage during the "call for failures." Overall, the experience was wonderful and with buckets of coffee I was able to meet people from a variety of industries to understand how we all have dealt with the complexity of modern software deployment and site reliability.
The Pearl is a gorgeous event space in the Dogpatch area of San Francisco. It features a large auditorium area, a mezzanine, and a rooftop space with peaceful views of the neighborhood. The organizers of the conference had really decked the place out well --especially for their first event. That being said, it was admittedly San Francisco to the point of stereotypes. Gender-identifying stickers in the bathroom, chia-seed pudding for breakfast, compostable everything, and a space reserved for relaxing with a cup of observabili-tea. But it was great! It was a welcoming and unpretentious environment. The focal point of the conference, small open-space discussions clustered around attendent-submitted topics, were split out around the various corners of the venue. This discussions helped guide the whole discussion of the definition and sharing of best practices of implementing and striving toward observability.
I went into the conference skeptical. My team lead had recommended I attend because he has a great respect for Charity Majors and the work she has done in the system monitoring and SRE space. When the emails and Slack channel flooded in about all of these buzzwords and open-space discussions, I was a little panicked. I wasn't trying to go to a meeting of On-Call-Engineers-Anonymous. Where would the sponsor swag? Furthermore, I was going to this conference without knowing anyone. Regardless, I submitted my talk about taking down our live environment, and got ready to take a Thursday off to go to the City.
- Methods of replaying live traffic in test environments
- Auto-documenting infrastructure
- How to leverage observability between all business units
- Understanding and circumventing autocatalytic system issues (I'd been reading some Bucky)
- How to comprehend complexity
- Finding the definition of observability was the ostensive goal of the event.
- Definition
- Combating the experience of running into an event horizon of complexity where tooling isn't sufficient
- Identifying what was sent to production/its implications
- Software is opaque by default. In order to understand a system, it must generate contextual and highly cardinal data so we can understand it as humans.
- Complexity
- GIFEE - Google's Infrastructructure For Everyone Else - do we need it?
- Complexity isn't just in huge systems, it can appear in any distributed system
- Problems worth investing in are ones that make your business exist
- Software is eating the world
- Complexity in integrations and connections
- Increasing the layers of abstractions that hide, but don't eliminate increasing complexity
- The new model of systems architecture:
- Maintaining high availability
- Service discovery
- There is no time for maintenance
- Software is still going to break
- Toward Observability
- Unstructured logs/metrics/monitoring -> Structured logs/events/stack trace alerts/time series metrics
- All events that failed tagged with the reason for failure in a searchable way
- Turning questions into queries quickly
- Data can define who owns an issue, who it impacts, severity etc
- Important Metrics
- Backend services
- Success rates (avg as well as min/max)
- Identification of states
- Ability to track historical state changes for account
- Dates and times when an account was broken and why etc
- Derived from structured logging of activity
- But logs are expensive, clean out the clutter
- Interface design
- Log every significant interaction
- Page load
- SPA navigation
- Errors
- Field entries
- Psychological markers
- Rage clicks
- Measure time to complete tasks
- Heatmaps of interaction
- Tools
- Dashboards are mostly flashy, but they require in-depth analysis tools alongside them.
- Commit tools-- no comment? no commit
- Building Fault Tolerance
- Formal verification is impractical due to illusive compositions of services
- State of the art has two approaches
- Chaos Monkey - random server black-holing
- Experts - precise server black-holing
- These approaches are lacking in automation and democratization
- Suggestion: Lineage Graphs
- In a model of a system, draw all possible lines from sender to receiver
- Only the set of nodes that prevent all possible lines can be considered a fault
- Observability For All-- who else can benefit
- Customers
- Especially when customers are developers
- Status pages/dashbboards
- Biz Ops/ Biz Int
- Marketing
- Strategy
- Closing the feedback loop
- Designers
- UI/UX iteration
- Finding the labyrinths in use
[ A ]
/ \
[ B ] [ B ]
\ /
\ /
[ C ]
|
[ D ]
- Struggles
- Dashboards cause fatigue
- Runbooks are almost always out of date
- Any simple task that could be outsourced could just be automated or dealt with in business hours
- Any complex issue is going to require an escalation that would waste valuable mttr
- On-call drains the company's best engineers 24/7
- Takeaways
- The best on-call systems are cyclical, feeding the learnings of each incident into the metrics
- The strongest post-mortem outcomes occur when there is extensive high-level buy-in and accountability
- On-call rotations should seek to balance suffering and business operability
- Shrinking the divide between dev/ops -- devs are ability, ops are empowerment, put them both on call
- Next Steps
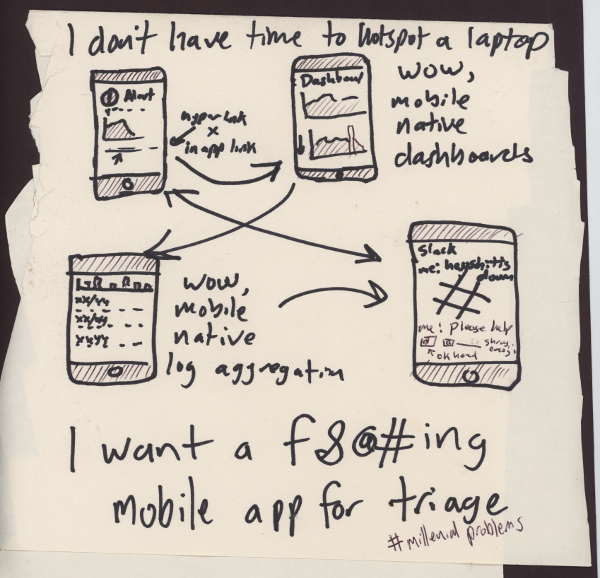
- There isn't a good phone-based incident triage system
- I want to be able to diagnose the severity of an incident and prioritize my attention
- Getting perfect alerts (no false positives/negatives) is not a reasonable expectation in a dynamic system and is not a valuable use of the team's time.
- Use the buddy system for new engineers
- The codebase is rarely best practice, don't be afraid to propose an alternative
- New engineers are uniquely poised to be the change
- Leave breadcrumbs everywhere
- Build a culture of perpetual on-boarding
- Rotate jobs
- Document every issue encountered in some fashion
- Document the justification for every commit
- Standardze documentation
- Document Jenkins builds too
- Blog posts as the torch bearers of technology and best practices
- Sometimes the best solution to a problem is to do nothing
- Focus on the low-hanging fruit, improving the experience the most with the least amount of effort
- A technology isn't really successful until it is boring, until it is hard to drive down the wrong side of the highway
"Nines don't matter if the user isn't happy" -Charity Majors
"We're more likely to be paged by a server issue impacting nobody than a client issue impacting everybody"
- On Call
- I have yet to experience a good emergency phone-bridge system
- Clunky phone systems versus chaotic and always-on slack channels
- Automated runbooks are considered state-of-the-art, but can be either useless or actually harmful if they are not kept up to date
- Everyone wants developers in the rotation
- Certain pages should allow the automatic escalation to multiple parties
- Tools I learned about
- Rookout - production data gathering/breakpoints
- Honeycomb - data analysis/error and trend debugging
- Flowtune - visualizations of infrastructure and service degredation
- Duo Labs Cloud Mapper - understanding complex cloud infrastructure
- Misc
- Backups are important. Always.
- The risk is not load, but a lack of load
- Never scale to 10x -- assumptions are flawed
- Release is just the stage in the middle of testing
- Released code is not canonical
- Tag all requests with extensive context data
- Requester metadata, response data, exception information
A couple months before the conference, a Call for Failures (CFF) was put out, asking for anyone to share a story of a time they royally screwed up/troubleshooted a problem. The presentations were to be short, five minute or so overviews of the incident and resolution. This segment was coordinated by pie (Rachel Perkins) and it was great fun to get up and listen to and share stories of operations gone wrong. It was affirming and participatory in the best way.
I got an email for the last day of the call for failures about an hour after I had accidentally taken down my
company's entire playerbase via a bad entry in AWS. Obviously this was a sign to share my experience. Being
in the video game industry, this presented a unique use case for observable, human-resilient systems on a
tight budget. I was able to share the stage with a former Israeli intelligence agent and a mechanical
engineer, who each had different interpretations and responses to failure. It was cool and I wasn't really
that afraid to go on stage!